At the beginning of every year (not so much the beginning this year), I take the time to update my records of what I’ve read the previous year and write up a summary.
I’ve continued to keep track of my reading using Goodreads.
My profile has nearly the full list of the books I’ve read since 2010.
2023 Goals
Last year I wrote:
I’d like to do a better job of keeping track of my reading. This should be pretty easy to do.
I don’t feel too bad about the reduction in reading but I’d like to read more this year. Some of my reading time has been replaced with worthwhile endeavors but not always.
Reading rejuvenates me. I need to keep it a regular part of my life.
Well, I don’t remember how poorly I did in 2022 of keeping tack of reading but I don’t think I did a great job in 2023.
Was it better than 2022?
Perhaps.
I didn’t write many reviews for specific books nor did I send out any emails about what I was reading throughout the year.
But I did do fewer corrections of the data I had in Goodreads.
I did read more than I did last year.
If I were grading myself on how well I achieved my goal, I’d give myself a B.
Highlights
Below are the highlights from 2023.
Any title link will bring you to Goodreads.
I started off the year with this book and really enjoyed it.
It is a pandemic story that has characters spanning hundreds of years.
It is a little weird and beautiful.
It did an excellent job of conveying feeling.
This is one of the few books that I did a mini-review of when I finished it.
That review:
A beautiful novel. While reading, I found myself rereading parts. Not because the sentences were confusing but because they expressed such a clear feeling.
A friend offered to send copies of this books to anyone who was up to reading it and I’m glad I spoke up and asked.
Each chapter presents a philosophy.
And the next chapter usually presents a different, conflicting philosophy.
Every chapter is small, so it is easy to read a bit and take some time to reflect.
I have mixed feelings about including this book on the list.
I reread this series when I was debating watching the television show.
Even on a second read, I still enjoyed this story.
Is it complex and view shattering science fiction?
Nahh, not really.
This is a really well done book that explores a modern gladiator system of punishment for criminals.
It is dark and creative and a solid commentary on modern society.
Fiction continued to dominate the book count this year.
If I did this by page count I think it would tell a different story, as I read quite a few short stories published as Kindle books and this skewed my fiction book count high.
I’ve continued to keep track of my reading using Goodreads.
My profile has nearly the full list of the books I’ve read since 2010.
This year I did a poor job of keeping Goodreads updated.
I had somewhat stopped updating Goodreads, or at least caring if I did it accurately, because I thought they were killing the ability to export your data.
Luckily, that feature hasn’t been removed so I’m going to continue using the service.
2022 goals
Last year I wrote:
I used to be pretty good at capturing some thoughts upon completion of a book.
I haven’t been doing a great job of that.
I’d like to do better this year.
We’ll see what that entails but it might take the form of having more discipline around sending out some thoughts in the newsletter.
I accomplished absolutely nothing related to the goals I wrote at the beginning of 2022.
I didn’t write down thoughts on books closer to when I finished them.
I didn’t keep my Goodreads data updated.
I didn’t send out updates to my newsletter.
Highlights
Below are some highlights from 2022.
The titles link to Goodreads.
I didn’t write many reviews on Goodreads this year and did not write detailed reviews in this article.
I’d encourage you to click the links and read reviews on Goodreads.
I found this book fascinating and it made me interested in breathing.
It was a nice mix of self-experimentation and reporting on studies.
The history of the shape of our faces and how it affects breathing really hooked me into this book.
I enjoyed the book enough that I also listened to a significant portion of it while on a road trip so my partner could also consume it.
To say I like Murakami’s writing would be an understatement, so reading a collection of essays by him about his writing was a pleasure.
I learned a bunch about Murakami and his journey to becoming an internationally renowned author.
At least as presented by Murakami, aspects of his life seem as surreal as some of his books.
This didn’t earn five stars because I found myself just not caring about some of the topics.
But overall, solid book, especially for someone that enjoys Murakami and enjoys reading about writing.
Here is a breakdown of books finished by month.
There were even a couple months where I allegedly didn’t finish a single book, though I wonder if that is actually true or of it is a data issue.
Electronic books continue to be the dominant format.
Audio book could be 0.5 for how much I listened to Breath while on a road trip.
I’d like to do a better job of keeping track of my reading.
This should be pretty easy to do.
I don’t feel too bad about the reduction in reading but I’d like to read more this year.
Some of my reading time has been replaced with worthwhile endeavors but not always.
Reading rejuvenates me.
I need to keep it a regular part of my life.
Have any book recommendations?
Please shoot me an email or leave a comment.
Bookmarklets, little snippets of JavaScript that you keep around as a bookmark, are useful.
They let you execute some JavaScript to perform almost any action you want on a website.
Some bookmarklets I use on my desktop browser include:
A collection of bookmarklets that let you change the playback speed of most embedded videos.
A bookmarklet to manipulate the URL of the page you’re visiting.
A bookmarklet to save the current page’s URL to pinboard.in.
For years, I thought I was restricted to only using bookmarklets in my desktop web browser.
I hadn’t effectively used mobile bookmarks before and thought that clicking them would be a huge pain.
It turns out, I was wrong!
I recently learned that if you start typing a bookmark’s title into your mobile browser’s location bar, it will let you select the bookmark.
This means you can easily execute a bookmarklet just by starting to type its name and clicking it when it appears.
This “search for bookmark in location bar” technique works with at least Google Chrome and Brave running in Android.
Below are the two bookmarklets I use regularly on my phone.
They exist to bypass paywalls.
This one prepends http://archive.is/ to the current URL:
To get them onto my phone, I added them a bookmarks on my laptop’s Chrome and synced them to my mobile phone.
Once in my mobile Chrome, I edited the bookmark in mobile Chrome, copied the code, and pasted it into a bookmark in Brave.
I type three characters into my mobile browser’s location bar before I can select either of these bookmarklets.
That is quicker than editing the URLs by hand and has improved the experience of reading articles on my phone.
At the beginning of every year, I reflect on books I’ve read in the previous year.
I take a look at my records, fix errors, and think about reading goals for the upcoming year.
I’ve continued to keep track of my reading using Goodreads.
My profile has nearly the full list of the books I’ve read since 2010.
Here is my 2021.
2021 Goals
Last year I wrote:
I have quite a few unread books sitting on my virtual and physical bookshelf.
This feels like setting a really low-bar but this year I’d like to read some of these unread-but-owned books.
I’m also planning on reading at least one book on writing and one book on climbing.
This goal is almost a subset of the above goal as I have books on both these topics sitting on my shelf.
Did I achieve those goals?
No.
Looking through my list of read books, I think only one of those a book I owned at the beginning of 2021.
I did not read some already owned books; I read a single already owned book.
I did read a book on writing, George Saunders' A Swim in a Pond in the Rain, and multiple climbing books, Rock Climbing Technique by John Kettle and Rock Climbing in Kentucky’s Red River Gorge by James Maples.
Early in 2020, at the request of some readers of this site, I started a mailing list.
During 2020 I used this newsletter as a way to notify subscribers of new articles posted to this website and write up short blurbs on books I had finished.
Except for a single email, I also didn’t send out any updates to the newsletter.
This is partially because I didn’t write many articles last year.
I generally try to write about one article a month but I did not do that in 2021.
We’ll see if I pick back up this habit in 2022.
Highlights
Below are some highlights from 2021.
The titles link to Goodreads.
I didn’t write many reviews on Goodreads this year and did not write detailed reviews in this article.
I’d encourage you to click the links and read reviews on Goodreads.
This was my third time reading Dune.
I read it in preparation for seeing the 2021 film.
I’m a huge fan of Dune but parts of it definitely haven’t aged well.
I think the story manages to be complex and have plenty of movement but somehow isn’t overwhelming.
I thought the film did a pretty good job of capturing that.
The first time I read Dune, I also made the very first Kindle Dune Dictionary.
If you are reading on a Kindle and haven’t read the book before, I’d recommend purchasing the dictionary.
I didn’t find it useful on my third time through the book but it made my first read through better.
In August and September, I pretty much devoured the entire Vorkosigan Saga.
I read all these books pretty much back to back and can barely distinguish them.
I’d recommend the series.
It was a fun series and there are quite a few books in it.
For some reason, this book stood out and is the only one I gave five stars.
The book starts with what feels like a collection of short stories and grows into a story of struggle, triumph, and failure.
I can’t point to what made this book stand out to me but a I really enjoyed it.
It might have had some moments that dragged a bit but I still loved it.
A solid book on the benefits of rethinking your positions.
A very short summary is that it is good to update your beliefs and be curious.
There is little benefit to being wrong longer.
Learn how to rejoice in correcting your beliefs and embrace updating your viewpoints.
There is a some overlap of concepts in this book and the book Moral Tribes.
If you are also well-versed in cognitive biases, parts of this book will be a repeat.
I think a second edition came out immediately after I finished reading the first edition.
Hopefully the second edition has high quality updates as the original edition of this book is pretty solid.
I’ve lived the vision promoted by this book and it is a good place to be.
A short book full of specific drills that are intended to improve your skill in climbing.
This book isn’t about improving your strength, flexibility, or endurance.
It is all about getting better at movement and paying attention to your movement patterns.
I’ve taken some of these drills and incorporated them into my climbing practice.
I plan on digging back into this book and incorporating more of them.
This book is a mix of the author’s personal experience, policy, and science and makes the argument that drugs should be legal.
Probably worth reading if you have any sort of reaction to that last sentence.
Reading some reviews on Goodreads gives a fairly balanced view of what this book is about.
Even if I personally gave this book five stars, I find myself agreeing with a wide range of reviews by others.
A couple other reviews (one, two) described this book as comforting science fiction.
I think that is a great description.
The world feels cozy.
It is full of generally nice folks going about their lives and interacting with each other over tea.
This main character in this book is non-binary and you get to hang out with them as they live their life.
It feels like a nice place to be with reasonable folks and respect between humans, nature, and robots.
It is a relaxing read that feels like a gentle fable that muses on life and what it means to exist.
This book has a very narrow audience.
If you have heard about the Red River Gorge, rock climb, and are interested in the history of the area you should read this book.
I learned a lot about one of my favorite places to rock climb.
There is a really good chance I should have given this book five stars.
It was great.
This book tells the story of the Hildebrandt family through interweaving perspectives of the family’s members.
The characters are complex and the perspectives are interesting.
I hope Franzen can continue to deliver this level of story in the sequels.
This book was beautiful.
It manages to feel slightly off and this is completely appropriate given the narrator.
This leads to some really amusing bits of writing.
Stats
I thought I had read less this year than I had in recent years but I was wrong.
I read 57 books and 19,564 pages in 2021.
Here is a breakdown of books finished by month.
I can tell from looking at August and September that I started and finished the Vorkosigan series during those months.
Electronic books continue to be the dominant format.
I used to be pretty good at capturing some thoughts upon completion of a book.
I haven’t been doing a great job of that.
I’d like to do better this year.
We’ll see what that entails but it might take the form of having more discipline around sending out some thoughts in the newsletter.
Have any book recommendations?
Please shoot me an email or leave a comment.
You might write tests as a way of driving the design of your software.
Other tests might be written in response to a discovered bug and, if written first, those tests you know when you’ve fixed the bug and act as guardrails preventing the reintroduction of that bug.
Tests can also be used to confirm you haven’t changed behavior while refactoring.
Tests can also be used as documentation.
Unlike non-executable documentation, tests will always match the implementation’s behavior.
An example in a comment or other documentation deserves to be in a test.
Take the following sketch of a Clojure function:
123456789
(defn confobulate"Takes a string and transforms it to the confobulated form. Examples: - \"alice\" -> \"EcilA\" - \"//yolo1\" -> \"//oneOloY\" "[s](-> s;; insert some work here, not going to implement this))
The docstring has examples in it to aid humans in understanding its behavior.
These examples are useful!
But they stop being useful and start being dangerous when they stop being accurate.
We can use unit tests to keep examples like this correct.
You can write comments near the assertions letting future readers know about the documentation that needs to be updated if behavior changes.
1234567
(deftestconfobulate-should-ignore-slashes;; If this assertion changes the docstring needs to be updated(is(= "//oneOloY"(confobulate"//yolo1"))))(deftestconfobulate-reverses-and-capitalizes;; If this assertion changes the docstring needs to be updated(is(= "alice"(confobulate"EcilA"))))
Any example in a comment or other non-executable documentation should be an assertion in a unit test.
You’ve already taken the time to document the behavior; take the time to figure out how to document it in a way that will fail if the behavior changes.
The constants you use in unit tests matter.
Like test and variable names, they can improve the readability of your code and make it easier to understand test failures.
Imagine the following.
A new developer joins your team and asks a question about how the code resolves config values.
You are unsure of the details so you pair up with the new teammate to dig into the code.
You know the codebase uses a relatively simple key-value pair concept for configuration.
It reads keys and values from a known files and, based on some rules, either ignores or overrides values when keys are duplicated across files.
config-value is the function that looks up the value for a particular configuration key, represented as a string.
This function takes three arguments: an in-memory representation of the configuration files, the key to lookup, and the mode to operate in.
You know the mode is important in influencing how config resolution works but you don’t remember the details.
Luckily for you and your pair, the codebase has plenty of unit tests.
The two of you dive in and look at some tests, hoping to understand how config resolution works.
It is great that these tests exist but they could be clearer.
They aren’t terrible but you have to work a bit understand what is happening.
When reading (= "2" (config-value config "b" :dev)), what does "2" represent?
What does "b" mean?
You have to either keep the value of config in your brain or keep glancing up in the file to recall what it is.
This isn’t great.
This adds cognitive overhead that doesn’t need to be there.
There are a few ways these tests could be improved
One way is through using better constants.
Let’s do a quick rewrite.
These are the same tests but with different constants.
Those constants make a huge difference.
This change has made the tests more legible.
You no longer need to remember the value of config or keep glancing up at it to understand the assertions in a test.
You can read (= "from development" (config-value config "in dev+app" :dev)) and have a pretty solid idea that you are looking up a key found in both development.conf and application.conf and while in :dev mode expect the value from development.conf.
The new constants provide clues about what the test expects.
You can read and understand the assertions without keeping much state in your head.
This increases the legibility of the tests and is useful when a test fails.
Which of the following is clearer?
The second one is clearer.
You can read it and form a hypothesis about what might be broken.
Well chosen constants reduce the state a person needs to keep in their head.
This makes tests easier to understand.
Good constants also make test failures easier to understand.
Just like good variable names, good constants increase the readability of our tests.
It is well worth placing some extra thought into the constants found in your tests.
At the beginning of every year I reflect on my reading from the previous year.
I take a look at my records, fix errors, and think about reading goals for the upcoming year.
I’ve continued to keep track of my reading using Goodreads.
My profile has nearly the full list of the books I’ve read since 2010.
Here is my 2020.
2020 Goals
Last year I wrote:
I was encouraged by how many non-fiction books I read this year and how many of them ended up earning a five star rating. I’d like to continue that trend of reading high-quality non-fiction books.
I’ve also been reading a lot of books but I haven’t always been the best at trying to consciously apply the lessons from those books. I’m going to try to improve that this year.
Those are pretty fuzzy goals but I’m alright with that.
I’ll come back at the end of this article and reflect on if I hit it or not.
Highlights
Here are my five star books from 2020.
The titles are affiliate links to Amazon.
If you click one and make a purchase I get a small kickback.
If I wrote a review on Goodreads then the my review link will take you there.
In the last couple of years, I’ve been writing fewer reviews on Goodreads than in the past so many books do not have a review there.
If you’re missing these reviews, I have started sending out an email every month or two and it frequently includes small reviews of what I’ve read since the previous email.
You can subscribe to that here.
The Hard Truth: Simple Ways to Become a Better Climber by Kris Hampton
This is an excellent dose of wisdom about climbing and improving your performance.
It does this through suggestions of how to change your mental relationship with climbing.
Improving is about putting in the work, reflecting, and trying hard.
The Body Keeps the Score: Brain, Mind, and Body in the Healing of Trauma by Bessel A. van der Kolk
I really enjoyed this book and made hundreds of highlights while reading it on my Kindle.
I’d suggest reading reviews on Goodreads and seeing if it is something that would be interesting for you.
Come as You Are: The Surprising New Science that Will Transform Your Sex Life by Emily Nagoski
This was a good book that, unlike what the subtitle claims, did not transform my sex life.
But I didn’t go into it expecting that.
I’m not the main audience for this book but still got some value from it.
I particularly enjoyed the parts that talked about stress, responses to stress, and emotional systems.
How to Change Your Mind by Michael Pollan
This book is about psychedelics, such as LSD and psilocybin.
It combines the history of these substances, old and new research being done with them, and sort of a travelogue of Michael Pollan’s growing experience with these substances.
Why I’m No Longer Talking to White People About Race by Reni Eddo-Lodge
I devoured all of her writing this year, both fiction and non-fiction, and the highlights are above.
None of her writing earned less than four stars.
Between starting and finishing writing this article, I learned she published a new short story, Zikora, and immediately read it.
It was pretty great.
One of the reasons I enjoy reading fiction is that it provides a window into the experiences of others.
Chimamanda Ngozi Adichie’s writing does exactly this and does it with beautiful prose and compelling stories.
The Diamond Age by Neal Stephenson
This was a reread of the first Neal Stephenson book I read.
I wanted to reread this book as I had been recommending it as a relatively short introduction to Neal Stephenson’s writing but I was second guessing how much I enjoyed it.
I was wrong to second guess that.
This story was still great the second time through.
This book covers so much and feels prescient despite being read 25 years after it was originally published (February 1995).
Parable of the Sower and Parable of the Talents by Octavia E. Butler
Octavia Butler builds a new religion in this series and, honestly, that religion is tempting.
These are fantastic science fiction reads that explore human connections and what we could be as a species.
Other notable reads
These are books that for some reason I didn’t give five stars but I still think they are worth recommending.
All links below are to Goodreads.
I read this at the very beginning of 2020 and think that everyone should read it.
I highlighted a ton of passages and plan on going back and reviewing those passages.
I read this at the very beginning of 2020 and highlighted a ton of passages.
The book is about listening and how we do a bad job at it.
It includes suggestions about how to get better.
Pair this book with I hear you, a book I read last year, and you’ll have the tools to become a better listener.
This was a stupendous science fiction read.
It takes you on a wild journey into a far future where sentient beings can exist in software.
This was very close to receiving five stars but I kept getting bogged down in some of the explanations.
I know this is why some folks enjoy hard science fiction but that isn’t why I’m reading these stories.
This book delivers an interesting, complex, and very speculative far future.
If the blurb sounds interesting to you and you’re willing to put up some with advanced theoretical (real? fake? I don’t know) physics then pick this book up.
Stats
I read 43 books and 12,093 pages in 2020.
The data also doesn’t capture three books that I’ve started but have yet to finish.
Last year marks a decade of me tracking my reading and it was the second lowest page count in that decade.
For many reasons 2020 was an unforgettable year and one where I spent a lot of time at home.
I would have thought that would have lead to a large number of pages read but I think much of my time ended up being taken up by non-book reading activities.
For better or worse (probably worse), a lot of my time was spent reading articles about the on-going global pandemic, the USA election, and the other non-stop news cycle of 2020.
Between that and the increase in newsletters and podcasts I’m consuming, I’m not that surprised my book reading has taken a hit.
Here is a breakdown of books finished by month.
This graph tells a slightly different story than the one I presented above.
I did not finish many pages in January through March, the pre-pandemic time period in the United States.
Those months I was extremely dedicated to training for climbing and was starting a new relationship.
I’m very happy both of those took up my non-working hours during those months.
I was still commuting to an office from January till mid-March and would have expected more pages finished on the train.
I’ll blame podcasts for that as this year I did start listening to those while commuting, since I can enjoy those while walking to and from the train as well.
The number of books read in February is high because I read a short story collection where each story was published individually on Amazon.
Unsurprisingly, electronic books continue to be the dominant format.
I succeeded in reading a solid number of non-fiction books that earned a high rating.
I read fewer non-fiction books than fiction but managed to have more 5 star ratings.
I’m going to count this as successfully hitting the non-fiction part of my 2020 goal.
Did I get better at applying the lessons from books?
Not at all and I barely even tried to do so.
Definite failure here.
2021 goals
I have quite a few unread books sitting on my virtual and physical bookshelf.
This feels like setting a really low-bar but this year I’d like to read some of these unread-but-owned books.
I’m also planning on reading at least one book on writing and one book on climbing.
This goal is almost a subset of the above goal as I have books on both these topics sitting on my shelf.
It is interesting to have been collecting this data for a decade now.
I haven’t done much in the way around looking at multi-year trends but I think it might be interesting to do so.
If you have a book recommendation, feel free to reach out and contact me.
In my last article, Speeding up Magit, I showed how removing elements from Magit’s status buffer drastically reduces the time it takes to refresh this buffer when working in a large repository (from 4 seconds to around 0.348 seconds).
In a comment on r/emacs, someone wondered if the native-comp feature of Emacs might improve the Magit status refresh time.
This reddit thread was the first time I had heard of the native-comp feature.
This feature lives on the feature/native-comp branch of the Emacs repository and it compiles Elisp code into native code.
Many users have reported noticeable speed improvements using it.
The official development log and Emacs Wiki have more information about it.
I’ll provide more information about getting native-comp working on macOS after I answer the Magit speed question.
How did it change refresh times of the Magit status buffer?
The quick answer is that running Emacs with native-comp improved the refresh times of the Magit status buffer.
Below is a table of the various times.
12345
| Experiment | magit-status refresh time |
|-----------------------------------------+---------------------------|
| full magit-status with native-comp | 3.152 seconds |
| full magit-status without native-comp | 4.003 seconds |
| magit-status with many sections removed | 0.348 seconds |
Using native-comp, we’ve cut off about 0.85 seconds.
That is a pretty solid improvement.
Even still, that isn’t fast enough for how often I use Magit so I’ll be sticking with my Magit setup with many sections removed.
As a caveat, the timing with native-comp also includes upgrading Emacs from 26.3 to 28.0.50 (so I could have native-comp) and Magit from 20201111.1436 to 20201212.929.
As a result, the comparison to full magit-status without native-comp isn’t entirely fair as multiple variables have changed.
The comparison to time with sections removed is fair as I’m still using that setup (but with native-comp) and the timing is pretty much the same.
Getting native-comp on macOS
To enable native-comp you need to build Emacs from source.
I’ve done this before on Linux systems but this was the first time I’ve done this on macOS.
When browsing reddit, I found the build-emacs-for-macos project which has some helpful instructions for doing this.
I followed the instructions from the readme and picked the latest known good commit from this issue (at the time I did this be907b0ba82c2a65e0468d50653cae8a7cf5f16b).
I then updated my init.el based on instructions from in the build-emacs-for-macos project.
I haven’t had any issues since switching to this very new Emacs.
I don’t have numbers to back this up but it does feel faster.
Recommendation
I’d recommend giving the native-comp feature of Emacs a shot.
It wasn’t terribly challenging to get setup and it is nice to get a glimpse of what the future of Emacs might be.
That future is a bit snappier.
Magit is a great Emacs tool and by far my favorite way of interacting with git repositories.
I use Magit nearly every day.
Unfortunately, refreshing the magit-status buffer is sluggish when you are working in a large repository.
A few months ago, I became sick of waiting and investigated how to speed up refreshing the status buffer.
After doing some research, I learned about the magit-refresh-verbose variable.
Setting magit-refresh-verbose to true causes Magit to print some very useful output to your *Messages* buffer.
This output shows how many seconds each step of magit-status takes.
Here is the output for the large repo that caused me to look into this.
The total time is found in the last line and we can see it took four seconds.
Four seconds is an incredibly long time to wait before interacting with Magit.
You can change how much work Magit does by removing functions from the magit-status-sections-hook with remove-hook.
I looked at the timings and and tried removing anything I decided was slow and something I didn’t think I’d miss.
For me, that list includes magit-insert-tags-header, magit-insert-status-headers, magit-insert-unpushed-to-pushremote, magit-insert-unpushed-to-upstream-or-recent, and magit-insert-unpulled-from-upstream. I also removed magit-insert-unpulled-from-pushremote.
You remove a function from a hook by adding elisp similar to (remove-hook 'magit-status-sections-hook 'magit-insert-tags-header) to your Emacs configuration.
I use use-package to configure mine and below is what my magit section looks like.
Lines 20-25 remove the hooks.
I also hard-code magit-git-executable to be the full path of the git executable on line 5 because folks said this made a difference on macOS.
12345678910111213141516171819202122232425
(use-packagemagit:ensuret:bind("C-c g".magit-status):custom(magit-git-executable"/usr/local/bin/git"):init(use-packagewith-editor:ensuret);; Have magit-status go full screen and quit to previous;; configuration. Taken from;; http://whattheemacsd.com/setup-magit.el-01.html#comment-748135498;; and http://irreal.org/blog/?p=2253(defadvicemagit-status(aroundmagit-fullscreenactivate)(window-configuration-to-register:magit-fullscreen)ad-do-it(delete-other-windows))(defadvicemagit-quit-window(aftermagit-restore-screenactivate)(jump-to-register:magit-fullscreen)):config(remove-hook'magit-status-sections-hook'magit-insert-tags-header)(remove-hook'magit-status-sections-hook'magit-insert-status-headers)(remove-hook'magit-status-sections-hook'magit-insert-unpushed-to-pushremote)(remove-hook'magit-status-sections-hook'magit-insert-unpulled-from-pushremote)(remove-hook'magit-status-sections-hook'magit-insert-unpulled-from-upstream)(remove-hook'magit-status-sections-hook'magit-insert-unpushed-to-upstream-or-recent))
After this change, my magit-status buffer refreshes in under half a second.
What did I lose from the magit-status buffer as a result of these changes?
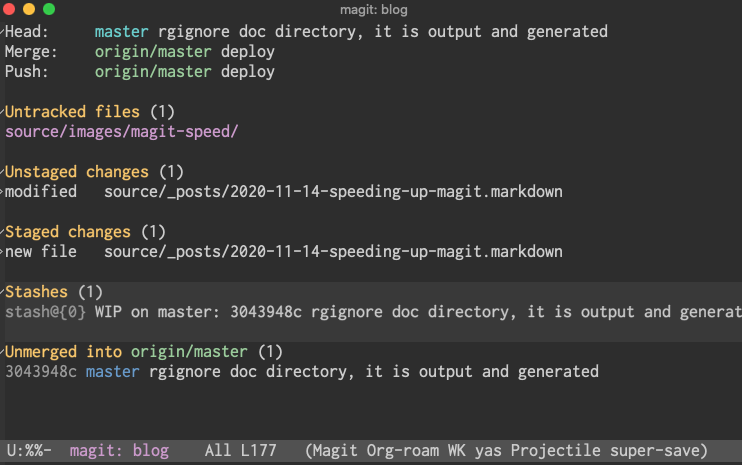
Here is screenshot of the original buffer.
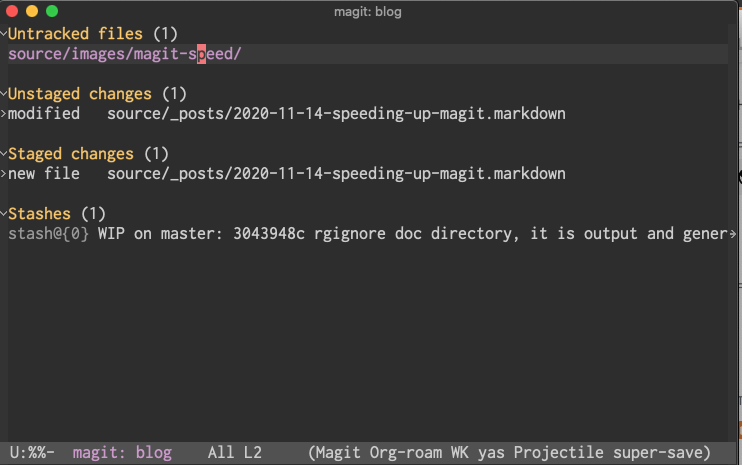
And here is the buffer after.
The difference is drastic1.
And so is the speed difference.
The increased speed is worth losing the additional information.
I interact with git very often and much prefer using Magit to do so.
Before these changes, I found myself regressing to using git at the command line and I don’t find that to be nearly as enjoyable.
Since I’ve made these changes, I’m back to doing 99% of my git interactions through Magit.
Don’t settle for slow interactions with your computer.
Aggressively shorten your feedback cycles and you’ll change how you interact with the machine.
Versions used when writing this article
This post was written with Magit version 20201111.1436 and Emacs 26.3 on macOS 10.15.7.
I’ve been using these changes for a few months but do not remember or have a record of what Magit version I was using at the time I originally made these changes.
edit on 2020/12/15: I recently upgraded Emacs to tryout the native-comp work and can report this still works with with Emacs 28.0.50, Magit 20201212.929, and Git 2.29.2 running in macOS 11.0.1.
Warning: This reduces the information Magit shows you. The status buffer will be blank if you have no changes. I find this tradeoff to be worth it.
The before image is even missing some sections that would have gone missing in the after shot since I didn’t want to put the effort.↩
Back in April 2013, I created and published a custom Kindle dictionary for the book Dune.
As far as I can tell, my Dune dictionary was the very first custom Kindle dictionary for a fiction book.
I created it because I was reading Dune for the first time and there were many unfamiliar words.
These words could not be looked up by my Kindle because they were not found in any of on-device dictionaries.
These words were in Dune’s glossary but flipping back-and-forth to that on a Kindle was a huge pain.
I initially worked around this by printing a word list from Wikipedia and carrying it with me.
This was better but it was still annoying.
I was so annoyed that I took a break from reading to figure out how to create a custom Kindle dictionary.
At the time, there wasn’t a ton of great information online about how to do this.
Eventually, I found Amazon’s Kindle Publishing Guidelines and, referencing it, managed to figure out something that worked.
The link in the previous sentence is to the current documentation which is much nicer than the mid-2013 documentation.
The earlier documentation left me with questions and required quite a bit of experimentation.
Using the mid-2013 documentation, I developed some Clojure code to generate my dictionary.
Doing this in 2013 was annoying.
The documentation was not good.
I recently read Greg Egan’s Diaspora and found myself wishing I had a custom dictionary.
I took a break from reading and packaged up Diaspora’s glossary into a dictionary.
I could have stuck with my 2013 generator but I decided to update it and write this article about creating a Kindle dictionary in late 2020.
The new documentation is a bit better but it still isn’t great.
Here is what you need to do.
Making a dictionary
Below are the steps to building a dictionary.
Construct your list of words and definitions.
Convert the list into the format specified by Amazon.
Create a cover page.
Create a copyright page.
Create a usage page (definitely optional).
Make an .opf file.
Combine the files together.
Put it onto your device.
1. Construct your list of words and definitions
There really are no set instructions for this.
Source your words and definitions and store them in some format that you’ll be able to manipulate in a programming language.
I’ve sourced words a few different ways.
I’ve taken them straight from a book’s glossary, a Wikipedia entry, and extracted them from a programming book’s source code.
2. Convert the list into the format specified by Amazon
Below is the basic scaffolding of the html file Amazon requires along with some inline styles that I think look decent on devices.
This has some extra stuff in it and also doesn’t contain everything Amazon specifies.
But it works.
<htmlxmlns:math="http://exslt.org/math"xmlns:svg="http://www.w3.org/2000/svg"xmlns:tl="https://kindlegen.s3.amazonaws.com/AmazonKindlePublishingGuidelines.pdf"xmlns:saxon="http://saxon.sf.net/"xmlns:xs="http://www.w3.org/2001/XMLSchema"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xmlns:cx="https://kindlegen.s3.amazonaws.com/AmazonKindlePublishingGuidelines.pdf"xmlns:dc="http://purl.org/dc/elements/1.1/"xmlns:mbp="https://kindlegen.s3.amazonaws.com/AmazonKindlePublishingGuidelines.pdf"xmlns:mmc="https://kindlegen.s3.amazonaws.com/AmazonKindlePublishingGuidelines.pdf"xmlns:idx="https://kindlegen.s3.amazonaws.com/AmazonKindlePublishingGuidelines.pdf"><head><metahttp-equiv="Content-Type"content="text/html; charset=utf-8"><style>h5{font-size:1em;margin:0;}dt{font-weight:bold;}dd{margin:0;padding:000.5em0;display:block}</style></head><body><mbp:frameset> [PUT THE WORDS HERE]
</mbp:frameset></body></html>
The [PUT THE WORDS HERE] part gets filled in with the markup for all of your words.
The basic structure for an entry looks like the following.
Every word has an <idx:entry> block followed by a <hr>.
These two elements together comprise a single entry.
The name attribute on the <idx:entry> element sets the lookup index associated with the entry.
Unless you are building a dictionary with multiple indexes, you can pretty much ignore it.
Whatever value is provided needs to match the value found in the .opf file we’ll make later.
The scriptable attribute makes the entry available from the index and can only have the value "yes".
The spell can also only be "yes" and enables wildcard search and spell correction.
The markup you use inside the idx:entry element is mostly up to you.
The only markup you need is the <idx:orth> node.
Its content is the word being looked up.
The rest of the markup can be whatever you want.
I wrap the term in a dt and the definition in dd because it just feels like the right thing to do and provides tags to put some CSS styles on.
I wrap the dt element in an h5 because I couldn’t figure out what CSS styles would actually work on my Kindle voyage to put the term on its own line.
It isn’t that I don’t know what the styles should be but my Kindle did not respect them.
Figuring out stuff like this is part of the experimentation required to produce a dictionary that you’re happy with.
There is additional supported markup that provides more functionality.
This includes providing alternative words that all resolve to the same entry, specifying if an exact match is required, and varying the search word from the displayed word.
Most dictionaries don’t need these features so I’m not going to elaborate on them.
3. Construct a cover page.
This is just a requirement of a Kindle.
Create a html file called cover.html and substitute in the appropriate values.
123456789
<html><head><metacontent="text/html"http-equiv="content-type"></head><body><h1>Dune Dictionary</h1><h3>Created by Jake McCrary</h3></body></html>
Amazon wants you to provide an image as well but you don’t actually have to do this.
You probably need to do this if you actually publish the dictionary through Amazon1.
4. Create a copyright page
This is also a requirement of the Kindle publishing guide.
There isn’t any special markup for doing this.
Just make another html file and fill in some appropriate details.
5. Create a usage page
This isn’t a requirement but I include another page that explains how to use the dictionary.
Again, this is just a html document with some content in it.
6. Make an .opf file.
This is one of the poorly documented but extremely important parts of making a Kindle dictionary.
This is a XML file that ties together all the previous files into an actual dictionary.
Make an opf file and name it whatever you want; in this example we’ll go with dict.opf.
Below is the one I’ve used for the Diaspora dictionary.
If you’ve created an image for a cover then lines 7 and 15 are the important and line 15 should be uncommented.
<?xml version="1.0"?><packageversion="2.0"xmlns="http://www.idpf.org/2007/opf"unique-identifier="BookId"><metadata><dc:title>A dictionary for Diaspora by Greg Egan</dc:title><dc:creatoropf:role="aut">Jake McCrary</dc:creator><dc:language>en-us</dc:language><metaname="cover"content="my-cover-image"/><x-metadata><DictionaryInLanguage>en-us</DictionaryInLanguage><DictionaryOutLanguage>en-us</DictionaryOutLanguage><DefaultLookupIndex>default</DefaultLookupIndex></x-metadata></metadata><manifest><!-- <item href="cover-image.jpg" id="my-cover-image" media-type="image/jpg" /> --><itemid="cover"href="cover.html"media-type="application/xhtml+xml"/><itemid="usage"href="usage.html"media-type="application/xhtml+xml"/><itemid="copyright"href="copyright.html"media-type="application/xhtml+xml"/><itemid="content"href="content.html"media-type="application/xhtml+xml"/></manifest><spine><itemrefidref="cover"/><itemrefidref="usage"/><itemrefidref="copyright"/><itemrefidref="content"/></spine><guide><referencetype="index"title="IndexName"href="content.html"/></guide></package>
An import element in this file is the <DefaultLookupIndex> element.
The <DefaultLookupIndex> content needs to contain the same value from the name attribute on your <idx:entry> elements.
The <DictionaryInLanguage> and <DictionaryOutLanguage> tell the Kindle the valid languages for your dictionary.
The other elements in the <metadata> should be pretty self-explanatory.
The <manifest> gives identifiers for the various files you’ve made in the previous steps
The commented out <img> shows how you’d add the cover image if you opt to have one.
For sideloading dictionaries onto Kindles, it is not required.
The <spine> section references the <item>s from the <manifest> and specifies the order they appear in your book.
I honestly don’t remember why the <guide> section is in there or what it is doing in this example.
I’m guessing that is what causes there to be an index with the word list in the dictionary but I haven’t tried removing it and the documentation doesn’t talk about it.
I only have it there since I had it in earlier dictionaries I made.
7. Combine the files together
The publishing guidelines (as of October 2020) tell you to combine the previously created files together using the command line tool kindlegen.
The problem with those instructions is that Amazon doesn’t offer kindlegen as a download anymore.
If you want to use it, you can still find it through the Internet Archive.
Instead of following the publishing guidelines, we’ll use Kindle Previewer to finish making the dictionary.
It is pretty straight forward.
The conversion log will complain about a couple things such as missing cover.
As long as these are just Warnings it doesn’t matter.
I’ve found the preview in this app doesn’t match what it looks like on your device so take it with a grain of salt.
7. Put it onto your device
Finally, put the dictionary onto your Kindle.
You can do this by either using a USB cable or by emailing it to your Kindle’s email address.
Once it is on your Kindle, open it up and double check that the formatting is correct.
Next, open the book you’ve made it for and try looking up a word.
If the lookup fails or uses another dictionary, click the dictionary name in the pop-up to change your default dictionary to yours.
Now when you try to look up a word, your dictionary is searched first.
The great thing is that if a word isn’t in your dictionary then the Kindle searches the other dictionaries2.
This feature is great as it lets your dictionary be very focused.
Hopefully Amazon doesn’t remove this feature.
End
It was interesting creating another dictionary so long after I made my first couple.
Some of the new features, like the ability to require an exact word match, would have been useful for my second dictionary.
The actual markup recommendations have changed over the years but luckily my Dune dictionary still works.
I’m not constantly checking that it works, so if Amazon had changed something and it broke, I probably wouldn’t notice until someone reported it.
The Kindle documentation is much better now compared to 2013 but it still isn’t great.
It is also a bummer that kindlegen is gone.
It was nice to be able to convert the input files from the command line.
I also think this means you can no longer make a dictionary from a Linux machine as I don’t remember seeing Kindle Previewer support.
If you’re ever in a situation where you think a custom dictionary would be useful, feel free to reach out.
Go forth and make dictionaries.
This is actually a challenge to do due to restrictions on what Amazon allows published.↩
No idea if it searches all of them in some order but I’m very glad it works this way.↩