I’m currently keep notes on my computer using plain text and Org mode.
I keep my notes in a git repository in my home directory, ~/org/.
I want my notes to be synced between my computers without me thinking about it.
Historically, I’ve reached for something like Google Drive or Dropbox to do this but this time I reached for git and GitHub.
Below is the script that I ended up cobbling together from various sources found online.
The script pushes and pulls changes from a remote repository and works on my macOS and linux machines.
The loop starting on line 38 does the work.
Whenever a file-watcher notices a change or 10 minutes passes, the loop pulls changes from a remote repository, commits any local changes, and pushes to the remote repository.
The lines before this are mostly checking that needed programs exist on the host.
I keep this running in a background terminal and I check periodically to confirm it is still running.
I could do something fancier but this isn’t a critical system and the overhead of checking every couple days is nearly zero.
Most of the time checking happens by accident when I accidentally maximize the terminal that runs the script.
I’ve been using this script for a long time now and I’ve found it quite useful. I hope you do too.
At the beginning of every year I reflect on the previous year of reading.
I take a look at my records, fix errors, and think about reading goals for the upcoming year.
I’ve continued to keep track of my reading using Goodreads.
My profile has nearly the full list of the books I’ve read since 2010.
This is my 2019.
2019 Goal
I have a stack of software and process books and I’d like to read through at least some of them (others are more reference books). I’m also going to bring over the 2018 goal of reading at least one book on writing. In a more general sense, I’m hoping to put some practices together that help me gain more from the books I’m reading. I’m still thinking through what that means. - Me last year
That was my goal for 2019.
In list form it looks like this:
Read some software or process books
Read at least one book on writing
Try to develop practices for getting more from books I’ve read
I read eight books related to the first goal and two (or three if I count an iffy one) related to the second.
That is enough where I feel pretty good about claiming I accomplished the first two goals.
I mostly failed on the third goal.
I was more aggressive about highlighting notes in my Kindle and I did occasionally look back at them.
Beyond that I didn’t do anything.
Highlights
Here are my five star books from 2019.
The titles are affiliate links to Amazon, so if you click one of those and make a purchase I get a small kickback1.
Accelerate: Building and Scaling High-Performing Technology Organizations by Nicole Forsgren, Jez Humble, and Gene Kim
This is a stellar book on practices of technology organizations that help build high performing companies.
If you work at a company that produces software in any capacity, I’d highly recommend this book.
This is a book that I’ve recommended to any coworker looking, and some not looking, for book recommendations.
Elements of Clojure by Zachary Tellman
This book has Clojure in the title but it is applicable to more than that language.
The book was published a section at a time and as a result I’ve read parts of it many times.
The content clearly shows that Zach has put a lot of thought into the topic.
A Tour of C++ by Bjarne Stroustrup
I’ve written C++ off and on since I started programming nearly 20 years ago.
Over those years, I’ve seen C++ transform as new versions were released.
Earlier in 2019, I was starting to write C++ again and this book was recommended by a coworker.
I had last written C++ back in 2013 and this book was a perfect way to refresh my stuck in early 2013 knowledge.
There is no fluff in this book and it is full of useful information.
Developer Hegemony: The Future of Labor
This is a tough read.
It isn’t tough because of difficult writing.
It is tough because it makes you depressed until you power through and reach the end.
This book delivers a very cynical look at corporations.
It provides guidelines for getting ahead and climbing the corporate ladder.
Then the book promotes an alternative approach, that of doing your own thing and going independent.
It makes a good case of it.
Beware of this one, it might make you question what you are doing with your career and life.
Digital Minimalism: Choosing a Focused Life in a Noisy World by Cal Newport
There is a common theme of awareness throughout many of the books I read and this book hits that theme.
This book can help you become a more thoughtful user of technology.
There are many useful recommendations in this book.
One of them is the suggestion that you can use social media and other technology differently than how the creators want you to use it.
In 2019 I wrote about how I use social media which shows how I apply this idea.
Effective Java by Joshua Bloch
I’ve read earlier editions in the past and decided to read the latest edition when it seemed like I’d be writing Java again.
This book is still good and a must read if you work with Java.
21 Lessons for the 21st Century by Yuval Noah Harari
This book covers a lot of ground.
Here is a quote from my friend Steven Deobald about this book.
Through stories and anecdotes woven into his almost unbelievably extensive research as a historian, “21 Lessons” is perhaps as entertaining and insightful as any other book I’ve read. It is accessible to anyone and the ideas presented regarding the fate of our species are stitched together beautifully. The arc of the 21 chapters has a progressive, almost orchestral, quality to it. Each chapter builds on all those which precede it and although some chapters have surprisingly variable writing styles, none feels like Harari is attempting to showboat or to force his medium into the overly artistic.
Draft No. 4: On the Writing Process by John McPhee
This was a pleasure to read.
I like reading books about writing and this is a good one that talks about McPhee’s approach towards creative non-fiction.
The Push: A Climber’s Journey of Endurance, Risk and Going Beyond Limits by Tommy Caldwell
What can I say?
I’m a sucker for books on climbing and learning more about the icons of the sport I love.
If you’ve watched the movie The Dawn Wall then some of this will be familiar to you.
The Nickel Boys by Colson Whitehead
This is a great book.
Go read the Goodreads page and pick it up.
The Great Believers by Rebecca Makkai
A friend of mine gave me a copy of this book and I’m glad she did.
It tells the story of the AIDs epidemic in Chicago.
This is a great piece of writing.
I’m not surprised at all that it has won many awards.
The Bonfire of the Vanities by Tom Wolfe
This book is great.
The satire just drips off the pages.
There are passages in this book where you can just feel the anxiety of the characters.
Every character is despicable and it is wonderful.
The Paper Menagerie and Other Stories by Ken Liu
This was my second time reading this book.
It is an excellent collection of short stories.
The first time I read this book, in 2016, I read the stories in order.
This time I took advantage of the Kindle’s estimate of how long a chapter would take and I jumped around, picking out stories that fit how long I wanted to read.
Both ways of reading this collection were excellent.
Exhalation: Stories by Ted Chiang
I absolutely loved Ted Chiang’s Stories of Your Life and Others and was excited when this collection of stories was published.
I had high hopes for this collection and I was not disappointed.
Some of the stories I had read prior to them being included in this collection but that didn’t matter.
I enjoyed reading the new stories and revisiting the previously published ones.
We don’t normally think of it as such, but writing is a technology, which means that a literate person is someone whose thought processes are technologically mediated. We became cognitive cyborgs as soon as we became fluent readers, and the consequences of that were profound.
That is a quote from a story in this collection.
It felt right to include it in an article about reading.
Golden Son, Morning Star, Iron Gold, and Dark Age by Pierce Brown
The four titles above are books two through five in Pierce Brown’s Red Rising saga.
I also read the first book in the series, Red Rising, in 2019 but it only earned a four star rating from me.
I obviously enjoyed this series and devoured it.
The books tell the story of a world full of inequality.
The world created is full of interesting characters and dilemmas.
Animal Farm by George Orwell
This was either my second or third time reading Animal Farm.
It is still good.
Reading it in 2019 and mapping in book behavior to the modern political climate was interesting.
Irresistible: The Rise of Addictive Technology and the Business of Keeping Us Hooked by Adam Alter
Yet another book that is at least somewhat about awareness.
This book talks about behavioral addiction but not just addictive technology.
Is it the single book out of the handful of books I’ve read in this space that I’d recommend?
No, but it is a good addition to my collection on the topic.
Permanent Record by Edward Snowden
I consider myself fairly knowledgeable about Snowden and what he did but I still learned more through this book.
One part I particularly enjoyed was Snowden reflecting on what has changed since his actions.
Another part I particularly enjoyed was Snowden’s telling of the early Internet.
This was an Internet where identities online weren’t necessarily tied to a real one.
I’m approximately the same age as Snowden and had similar experiences with being a young person during the early Internet days.
It was interesting to be reminded of that time while reading this book.
I highlighted a lot of passages and there are probably more I should have highlighted.
Atonement by Ian McEwan
This book was so close to being five stars.
I started reading this book because I mistook the title for that of a science fiction book I’ve been intending to read.
I’m glad I did.
It took me a little while to get into the book but once I did I was hooked.
Here is a review from one of my friends that captures some of what I felt about this book.
I Hear You by Michael S. Sorensen
It provides some guidance towards being a more validating person.
The book is short and to the point.
I’ve managed to take some of its advice and I think it has been useful.
Recursion by Blake Crouch
This was really good.
It is action packed and an interesting concept.
Version Control by Dexter Palmer
I really enjoy this book.
It tells the story of a relationship with bits of science fiction.
I really enjoyed my friend Dan’s review.
Stats
The page count numbers for 2019 books are a bit screwed up so I’m only doing a books per month graph this year.
Unsurprisingly, electronic books continue to be the dominate format.
I was encouraged by how many non-fiction books I read this year and how many of them ended up earning a five star rating.
I’d like to continue that trend of reading high-quality non-fiction books.
I’ve also been reading a lot of books but I haven’t always been the best at trying to consciously apply the lessons from those books.
I’m going to try to improve that this year.
Those are pretty fuzzy goals but I’m alright with that.
I’m not really sure why I bother doing this. I’d write these posts without this incentive and I think my lifetime earnings are maybe in the double digits.↩
I recently built an Atreus keyboard.
This keyboard is an extremely small keyboard with only 42 keys.
Below is the photo of my result.
As you can see, it has a split layout and the keys are aligned vertically and staggered.
Thanks to using Ergodox keyboards since 2014, I’m very used to this key layout and find it superior to traditional keyboards.
The keyboard is very small.
To give you an idea of how small it is, here is a photo of it next to one of my Ergodox keyboards and with a bit of my fingers in the shot.
Building the keyboard was pretty straight forward.
The included instructions are thorough and include plenty of photos.
All of the components are through-hole so the soldering is not difficult.
This would be a good first keyboard project.
I already had USB cable, key switches, key caps, and a micro-controller so I purchased the partial kit from Phil.
It came with everything else, except for something to coat the wood, that you need to build the keyboard.
I wanted to connect the keyboard to USB C ports, so I used a micro to USB C cable.
I enjoyed the color of the laser cut wood and appreciated the burn marks.
I didn’t want to lose the color or burns so I coated the wood with a water based clear polyurethane with a satin finish.
This was probably the most difficult part of the build, and it was pretty easy, simply because I lack experience finishing wood.
When reading other build logs I noticed that someone else put a zip tie on their USB cable to help prevent it from tugging on the micro-controller.
I have no idea how helpful this is but it seemed like a good thing to do so I also did it.
To do this you basically just wrap the cable with a zip tie and cram it against the case so that the zip tie prevents tugging on the micro-controller.
You can see it in the picture below.
I’ve only been typing on the keyboard for basically this blog post but I’ve already found myself adapting to it pretty quickly.
I don’t intend for it to replace my Ergodox for normal usage but I think it will be a great portable keyboard.
Overall it was a fun project and I’m glad I did it.
I look forward to customizing the firmware to make the key layout fit my usage.
I’ve owned a Onewheel XR for about a year now. It is a one-wheeled electric skateboard-like device that is super fun for zipping around Chicago.
When I first got it, I purchased a small guitar stand. It worked but it was always a bit finicky and I was never satisfied with it. I had to sit the Onewheel on it just right to have it stay on it without causing the legs of the stand to spread too wide.
This resulted in me buying a second guitar stand and trying that out. This one was even worse.
I grew frustrated with these non-purpose built stands and started looking into purchasing a Onewheel stand. There are plenty of beautiful stands out there, both officially from Future Motion and from third party vendors like The Float Life.
Then I remembered that my old coworker, Tom Marsh, built his own and put the plans online. This inspired me to go the DIY route.
I thought that a stand made out of pipe would look pretty good and be easy to construct. It also gave me a good excuse to ride my Onewheel to Home Depot.
I explored the plumbing section of Home Depot and bought a variety of pipe and pipe fittings and took them back home to experiment with putting them together.
I ended up building the stand below.
I think the above stand looks great and it was easy to build.
Here is the part list:
2 ½ inch x 8 inch nipple
1 ½ inch x 6 inch nipple
2 ½ inch x 3 inch nipple
2 ½ inch 90 degree elbow
2 ½ inch 3-way side outlet
2 ½ inch cap
I washed off the black coating using Goo Gone and then assembled the stand. This ups the risk of rust but I think that might actually look cool so I’m not too worried about it. You could optionally coat the pipes for some protection.
Once you have the parts the assembly is very straight forward. The only additional work I might do is to put some rubber feet on the bottom to prevent scratches to my floor.
Last fall I started to work in an office again. I’ve used a hand-built Ergodox for years now and really prefer working on it. This meant I needed another ergodox for the office. Luckily, now you don’t have to build your own. I bought an Ergodox EZ1.
The Ergodox EZ uses the QMK firmware. This has a lot of fancier options than the firmware I had been using on my hand-built ergodox.
This mostly didn’t matter and I just configured the Ergodox EZ to match my original Ergodox’s layout. Then I started a new job and found myself programming in Scala using IntelliJ IDEA.
Shockingly, after not using IntelliJ for years, I still remembered many of the keyboard shortcuts. This was great! Unfortunately, in my years since last using IntelliJ, I created some conflicting keyboard shortcuts for managing my window layout. These were mostly shortcuts that involved holding Command + Alt and pushing an arrow key. Luckily, the QMK firmware supports a Meh key.
What is the Meh key? It is a key that presses Control + Alt + Shift all at the same time.
This is great for setting up shortcuts that don’t conflict with ones found in most normal programs. This let me change my window manger shortcuts to use the Meh key and I was then conflict free.
I can’t handle having different shortcuts across different machines with the same OS, so I needed to needed to update my original Ergodox to use the QMK firmware so I could also have a Meh key at home. Luckily, the QMK firmware also works on it and, maybe even more luckily, the Ergodox EZ firmware just works with my original Ergodox.
This actually means I can simply take the compiled Ergodox EZ firmware and flash it straight to my Ergodox. Any time I’ve done this the keyboard keeps working.
Unfortunately, the LEDs in my original Ergodox are mostly hidden by non-translucent keys. These LEDs indicate when I’m not main layer and I find them really useful. I only have a single translucent keycap and would prefer only that LED to be used.
Here are the steps I took to make that change.
Use the graphical QMK Configurator to visually configure my keyboard layout. In the Keymap Name field, put jakemcc.
Click the Compile button in the above configurator.
Download the full source.
Unzip the source and edit qmk_firmware/keyboards/ergodox_ez/keymaps/jakemcc/keymap.c to include snippet of code below this list.
In qmk_firmware run make ergodox_ez:jakemcc.
Find ergodox_ez_jakemcc.hex and flash my original Ergodox.
This snippet gets added to the bottom of the keymap.c. It only turns on led 1, which is the one under my translucent key, whenever my keyboard isn’t on layer 0.
Now, I can use the fancy Meh key to be conflict free and easily tell when I’m not on my main layer. This is wonderful.
I bought one with Cherry MX Clear switches. I’ve since switched them to Cherry MX Browns. The clears were too firm for me. I did not get Cherry MX Blues because I didn’t want my fellow coworkers to be annoyed by the glorious clickty-clack of those switches.↩
Over the years, I’ve read many articles about the negative aspects of social media. You’ve probably read articles extolling the benefits of cutting social media out of your life. These articles are abundant and easy to find through a search for “stop social media” or “quit social media”.
Social media hasn’t played a significant role in my life for a couple of years. I first started being more mindful of how I consumed social media in 2013. Back then, I temporarily switched to using a feature phone (a non-smart phone) for a month and a half. This really reset my relationship with consuming media on a phone. Since my phone was my primary entry point into Twitter and Facebook, my usage of both plummeted.
Since then, I’ve continued to take a careful look at how I use social media and have made tweaks to get maximum enjoyment with minimal downsides. This has involved changing how I use the desktop web applications for both Twitter and Facebook1.
The following books have helped shape my thinking towards digital distractions. They’ve put into words some of the practices I stumbled into. They’ve affected how I use smart phones and how I approach social media.
One of the ideas in both Digital Minimalism and Essentialism is that you can pick and choose what you add to your life. This extends to individual features of products you use. This is something I arrived at prior to reading these books and it was nice hearing others putting this idea into words.
Below is how I’ve chosen to use various social media platforms.
Twitter
I only consume Twitter on my computer and I read it through Tweetdeck.
I don’t check my entire feed. Instead, I have Tweetdeck setup to display a few curated lists of accounts along with mentions and direct messages. One list is composed of close friends, another highlights some people in the software development space, and another contains some Twitter art projects.
Because I focus on a limited number of accounts, I don’t have an infinite list to scroll through. This focus keeps Twitter useful to me and allows me to check it every few days and still stay up to date on topics I care about.
I rarely tweet but when I do it is usually to promote my own or another person’s writing. I also occasionally tweet as an art bot.
Facebook
I only consume Facebook on my computer and mostly stopped using the website in 2016. The 2016 US presidential election made me realize I didn’t find the Facebook news feed useful. It did not add positive value to my life.
That is when I found the News Feed Eradicator Chrome extension. This extension gets rid of the news feed. It is great.
Without the news feed, I no longer open the site and mindlessly scroll through the firehose of updates. I no longer know what is going on in the curated lives of my friends that still use Facebook. That is ok. Now when I run into them in real life, I can catch up and learn about their kids and their lives. I can have an honest reaction to learning that someone got married instead of sort of already knowing it. Someone can tell me about a trip they took and can show me photos I’ve never seen before.
I haven’t completely deleted my Facebook account because it does add value to my life through a couple of groups and Facebook messenger. Only using these features has reduced the frequency I visit Facebook to once every few days. That is more than enough to keep up with what is going in in the Chicago climbing community and events going on at local climbing gyms.
I rarely post to Facebook but when I do it is often to promote something I’ve written.
Goodreads
I’m not really sure if Goodreads counts as a social media site. I use it to keep track books I want to read and books I’ve already read. It isn’t something that consumes any amount of my time mindlessly.
LinkedIn
I’m not sure if you can consider my usage of LinkedIn to be actual usage. It mostly results in email in my inbox that almost immediately gets archived. It does keep me somewhat informed about what job opportunities are out there though recruiter outreach.
I very rarely post anything to LinkedIn.
Instagram
I’ll completely admit that this is the social media platform that I waste time on. It is the only social media app on my phone and that increases how frequently I use it.
I signed up for Instagram in order to follow tattoo artists. This helped me learn what tattoo styles I enjoyed the most. This was a huge success and now I have a much better appreciation and eye for this art.
Eventually, my usage of Instagram expanded to follow some friends, local Chicago artists, and professional rock climbers. Following each of these groups is slightly beneficial but I’m not sure if it is an overall positive impact compared to the temptation to fill downtime with Instagram scrolling.
I’m approaching the point of deleting Instagram from my phone and experiencing that.
I post occasionally to Instagram both using the story feature and normal posts. These are usually photos of some street art or stickers put up in Chicago. It is very infrequent.
End
So that is how I consume social media. It mostly happens on my computer and I use a subset of features a platform offers. I’ve reached a point where I feel like I’m getting a lot of the pros without too many of the cons.
It is an area in which I’ll keep experimenting. I’d encourage you to as well. Try a different usage pattern for an extended period of time and then reflect on your changed behavior. Keep the changes that have made a positive impact.
Ignoring LinkedIn and Goodreads, I think Facebook and Twitter were the only social media platforms I used back then.↩
Today I released lein-test-refresh0.24.11. I don’t always announce new lein-test-refresh versions with an article but this release breaks some existing behavior so I thought it was worth it.
Each of these changes is the direct result of interacting with four different lein-test-refresh users. Some of this took place on GitHub and others through email. Thanks to all of you for taking the time to think about improvements and notice oddities and bring them to my attention.
Breaking change: Monitoring keystrokes to perform actions
Prior to this release, if you hit Ctrl-D then STDIN reads an EOF and test-refresh would quit. With version 0.24.1, test-refresh no longer does that. Instead, it stops monitoring for input and just keeps running tests. Since it stops monitoring for input it no longer notices when you hit Enter to cause your tests to rerun. You can still stop lein test-refresh by sending a SIGINT with Ctrl-C.
This change was made because there is some combination of environments where if test-refresh execs /bin/bash then it receives an EOF on STDIN. Before this change, that means test-refresh would quit unexpectedly. Now it will keep going.
Thanks Alan Thompson for bringing this to my attention and taking the time to help diagnose the problem.
You can supply your own narrowing test selector
Being able to tell test-refresh to narrow its focus by adding :test-refresh/focus as metadata on a test or namespace has quickly become a favorite feature of many users. Now you can configure a shorter keyword by specifying configuration in your profile. See the sample project.clj for how to set this up.
I’ve turned down this feature in the past but a narrower request came up and I thought it seemed useful. test-refresh now exposes a function you can call in a repl to run test-refresh in that repl. This makes the repl useless for any other task. To do this, first add lein-test-refresh as a dependency instead of a plugin to your project.clj. Then, require the namespace and call the function passing in one or more paths to your test directories. Example below.
This request was done so that you can run it in Cursive’s repl and gain the ability to click on stacktraces. Thanks Klaus Wuestefeld for bringing this up again with a really solid and focused use case.
Better output on exceptions while reloading
This was a pull request from Minh Tuan Nguyen. Now figuring out where to look for the error will be a little easier.
Thank you
Thanks to all the users of lein-test-refresh. I’ve found it to be very valuable to the way I work and I’m very happy that others do as well.
This was originally 0.24.0 but that had a bug in it. Sorry about that.↩
I was recently adding a feature to an internal web UI that caught all unhandled JavaScript errors and reported them to the backend service. The implementation went smoothly with most of the effort spent figuring out how to test the code that was reporting the errors.
If the error reporting failed, I didn’t want to trigger reporting another error or completely lose that error. I decided to log a reporting error to the console. I wanted to write a test showing that errors reporting errors were handled so that a future me, or another developer, didn’t accidentally remove this special error handling and enable a never ending cycle of of reporting failed reporting attempts.
It took me a while to figure out how to do this. I searched the web and found various articles about using Jasmine to do async tests. They were helpful but I also wanted to mock out a function, console.error, and assert that it was called. None of the examples I found were explicit about doing something like this. I forget how many different approaches I tried, but it took a while to figure out the below solution.
It takes an incoming event object and merges it with a default value and posts that to the backing service. fetch returns a Promise and the code handles errors by calling catch on it and logging.
Below is what I eventually came up with for testing the error handling feature of reportEvent.
This uses spyOn to mock out fetch and console.error. The fetch call is told to return a rejected Promise. The console.error spy is a bit more interesting.
The console.error spy is told to call a fake function. That function asserts that the console.error spy has been called. More importantly, it also calls a done function. That done function is a callback passed to your test by Jasmine. Calling done signals that your async work is completed.
If done is never called then Jasmine will fail the test after some amount of time. By calling done in our console.error fake, we’re able to signal to Jasmine that we’ve handled the rejected promise.
You don’t actually need the expect(console.error).toHaveBeenCalled(); as done won’t be called unless console.error has been called. If you don’t have it though then Jasmine will complain there are no assertions in the test.
So there we have it, an example of using some of Jasmine’s asynchronous test features with spies. I wish I had found an article like this when I started this task. Hopefully it saves you, and future me, some time.
Leiningen test selectors are great. They allow you to filter what tests run by applying a function to the test’s metadata. If that function returns a truthy value then that test will run. lein-test-refresh supports them and even includes a built in one for its focus feature.
I was recently asked if test-refresh could support filtering tests using a regular expression against the name of a namespace or test. Lucky for me, test-refresh already supports this because of its support of test selectors.
Most of the examples of Leiningen test selectors show very simple functions that look for the existence of a keyword in the metadata. We can do more than that. We can write a predicate that does whatever we want with the metadata.
To take a look at a test’s metadata, I generated a new project and looked at the generated default test file.
1234567
(ns selector.core-test(:require[clojure.test:refer:all][selector.core:refer:all]))(deftesta-test(testing"FIXME, I fail."(is(= 01))))
I then used my repl and to see what metadata was on the test.
You could write the above code is many different ways. Whatever you write, it needs to look for the existence of integration in either the test’s name or namespace.
If you wanted to make lein test or lein test-refresh only run non-integration tests you can add a default test selector to the project.clj.
Enjoy! I hope this example helps you run a subset1 of your Clojure tests through Leiningen test selectors.
Running a subset of your tests can be helpful and test-refresh has a few features that help you do that. If you can, I’d still recommend making all your tests fast enough to run them all the time.↩
The setup linked above works great for when I’m doing work all by myself. It showed a problem when using ssh and tmux to pair with another developer. Instead of both developers receiving a notification, only one did. One is better than none but not ideal.
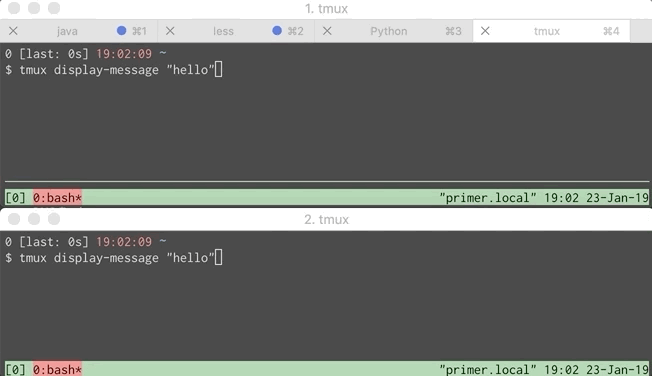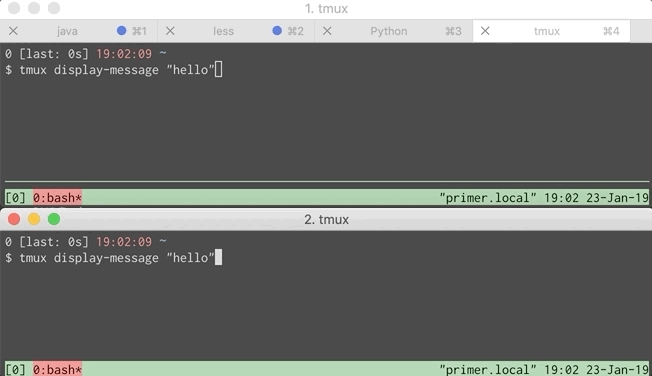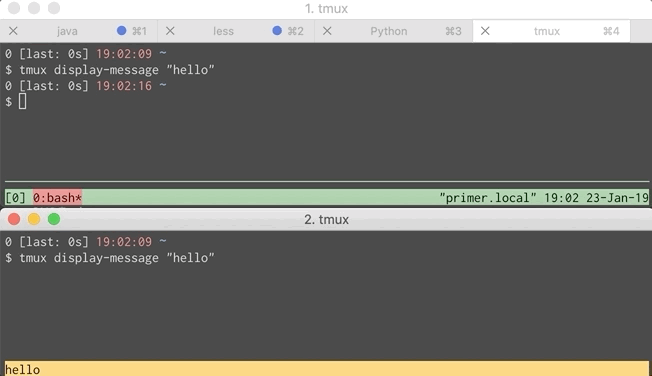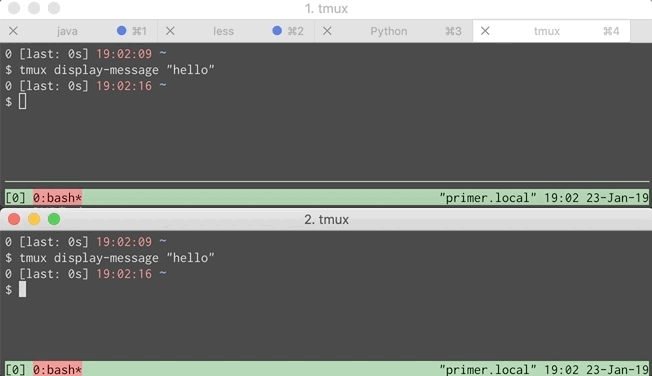
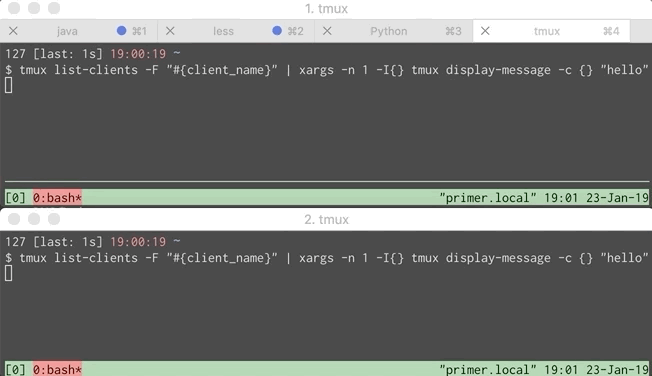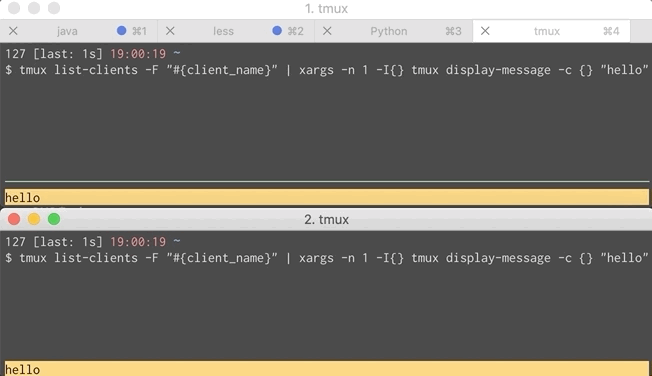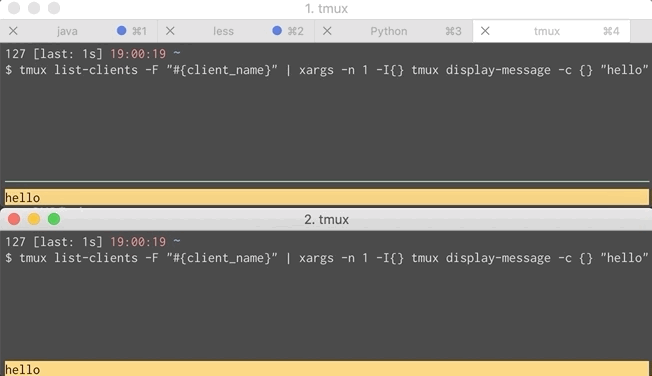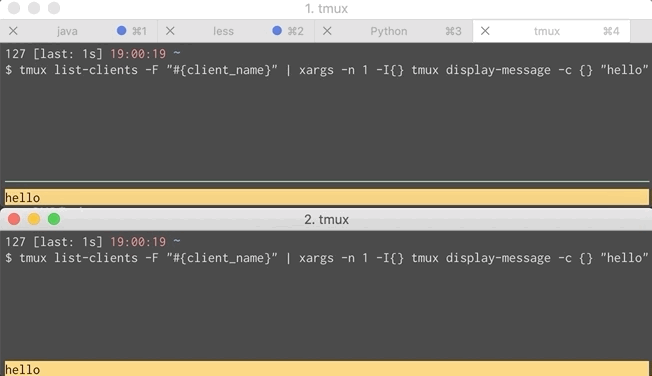
Below is a GIF showing the problem. Each window simulates a different developer.
This wasn’t too hard to fix. A little digging through the tmux manpage shows that tmux display-message takes an optional flag telling it which client receives the message. If we can get a list of all the clients then iterating over them and sending a message to each is straightforward.
tmux list-clients give us this list. Below is the output.
What we care about are the parts that look like /dev/ttys002. At first I used cut to grab these values but then I dug a bit deeper into the tmux manpage.
It turns out that you can specify a format to tmux list-clients. Running tmux list-clients -F "#{client_name}" gives us the output we care about.
We can combine that with xargs to send a message to multiple clients.
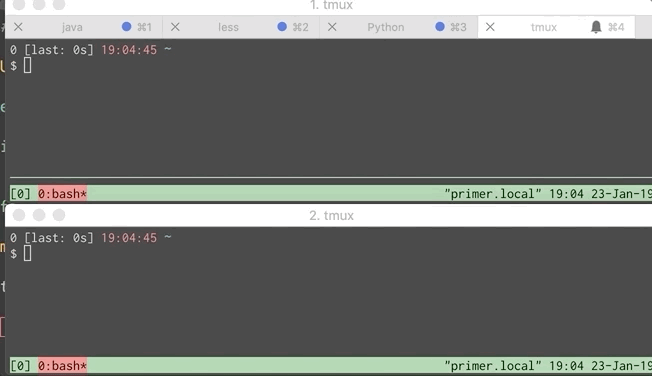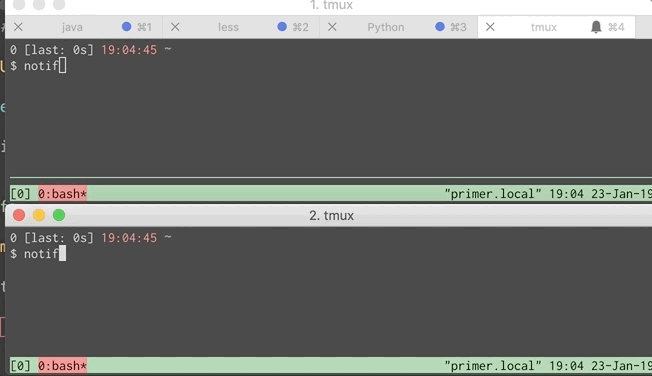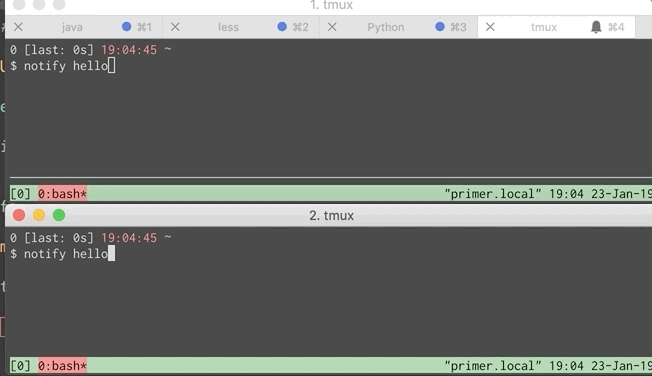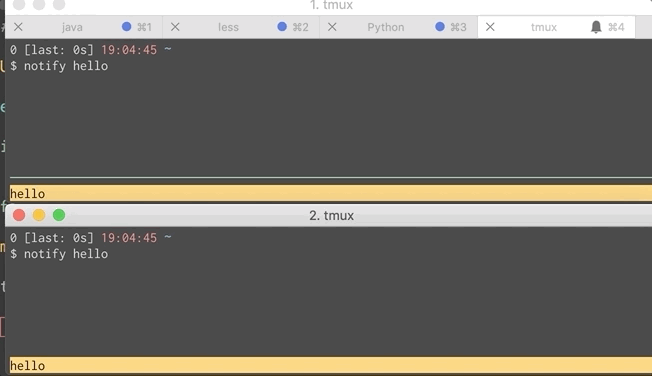
That command is a bit much to put into lein-test-refresh’s configuration so I shoved it in a script called notify and configured lein-test-refresh to use it. Script and GIF of that below. Now both you and your pair can get notifications.